Gemini API: Tại sao lại cần nó?
TLDR
Anthropic đã tập trung huấn luyện khả năng viết code cho Claude models, cho nên họ không đầu tư nhiều vào khả năng vision. Điều này làm cho chất lượng phân tích hình ảnh của Claude models không được tốt, ảnh hưởng đến workflow của việc phát triển phần mềm.
Lưu ý: Gemini API sẽ tốn phí, nếu bạn cảm thấy không cần, thì hoàn toàn có thể bỏ qua bước này!
Cách cài đặt
- Lấy key Gemini tại Google AI Studio
- Tìm
.env.example:
- Nếu bạn cài đặt ClaudeKit ở project scope: copy
.claude/.env.examplera.claude/.env - Nếu bạn cài đặt ClaudeKit ở global scope: copy
~/.claude/.env.examplera~/.claude/.env(nếu bạn dùng Win:%USERPROFILE%\.claude\.env)
- Mở file
.envra và điền vào giá trị củaGEMINI_API_KEY
That’s it!
Đoạn sau mình dẫn lại từ bài nghiên cứu cách đây không lâu của mình về:
Vấn đề về “đôi mắt” của Claude
Để có thể phục vụ công việc debug dễ dàng hơn, việc cung cấp screenshot để CC tự hình dung ra vấn đề là cần thiết. Mình rất hay dùng phương pháp này.
Nhưng gần đây mình phát hiện ra một điều, đó là mô hình thị giác của Claude khá kém, không được tốt bằng những mô hình khác của đối thủ (Gemini, ChatGPT,…)
Hãy nhìn vào ví dụ sau, Claude Desktop failed hoàn toàn so với Gemini và ChatGPT:
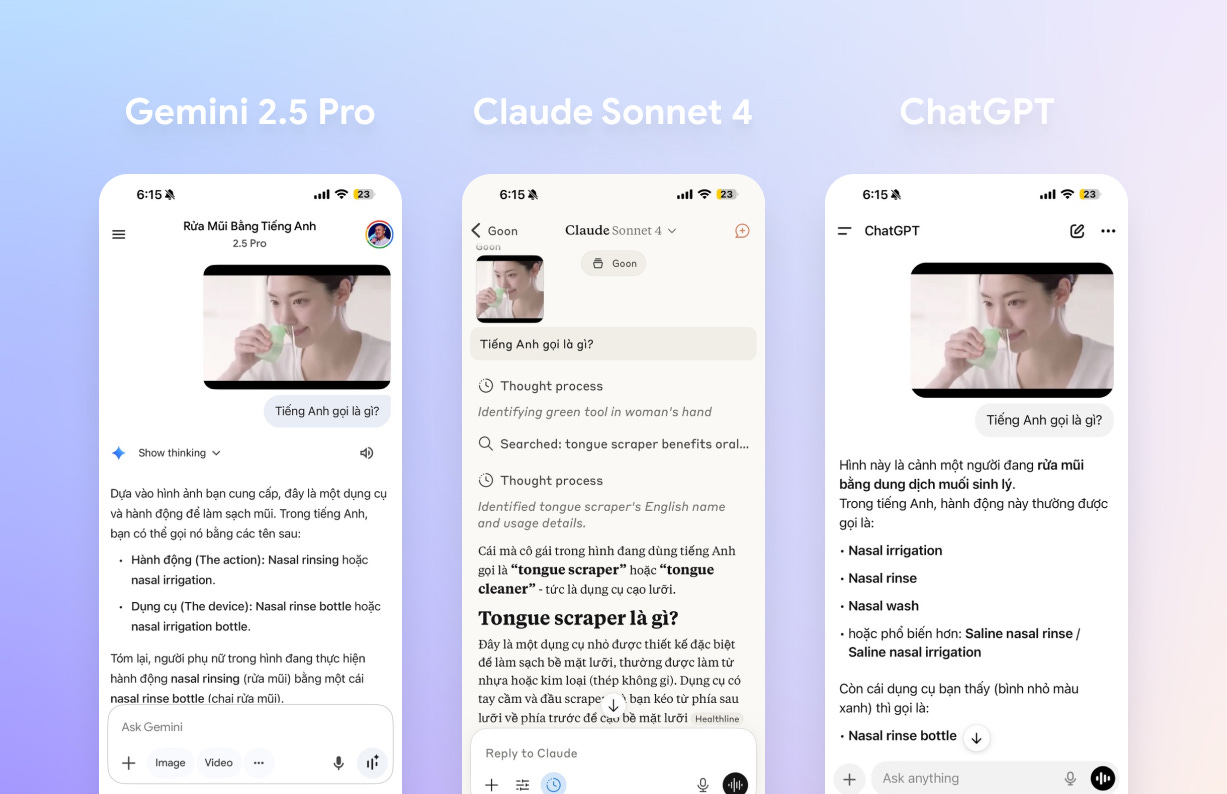
Claude không định nghĩa được đúng hành động và thiết bị trong hình.
Bây giờ thử so sánh trực tiếp trong Claude Code và Gemini CLI luôn nhé!
Mình sẽ thử yêu cầu cả 2 cùng đọc tấm hình blueprint và mô tả lại chi tiết những gì nó nhìn thấy:
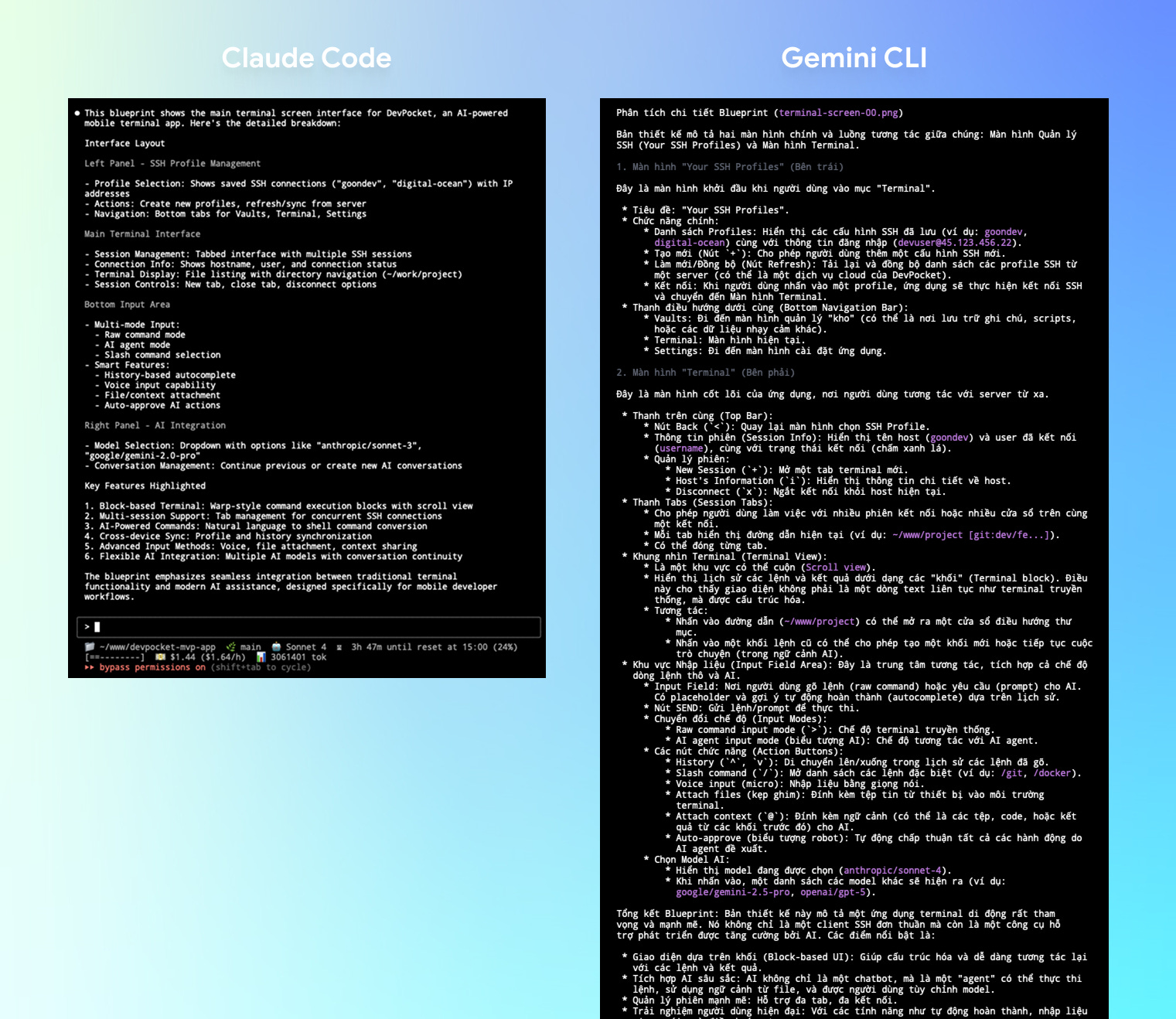
Gemini CLI cho kết quả chi tiết mô tả bản vẽ blueprint, trong khi Claude Code thì khá sơ sài…
Bạn thấy sự khác biệt rồi chứ?
Tiếp nè, còn một thứ nữa mà “đôi mắt” của Claude hiện đang KHÔNG THỂ làm được: đó là khả năng PHÂN TÍCH VIDEO
Nhưng Gemini (bản web, không phải bản CLI) lại có thể làm được điều đó, điều này giúp cho việc debug trong Vibe Coding trở nên dễ dàng hơn rất nhiều.
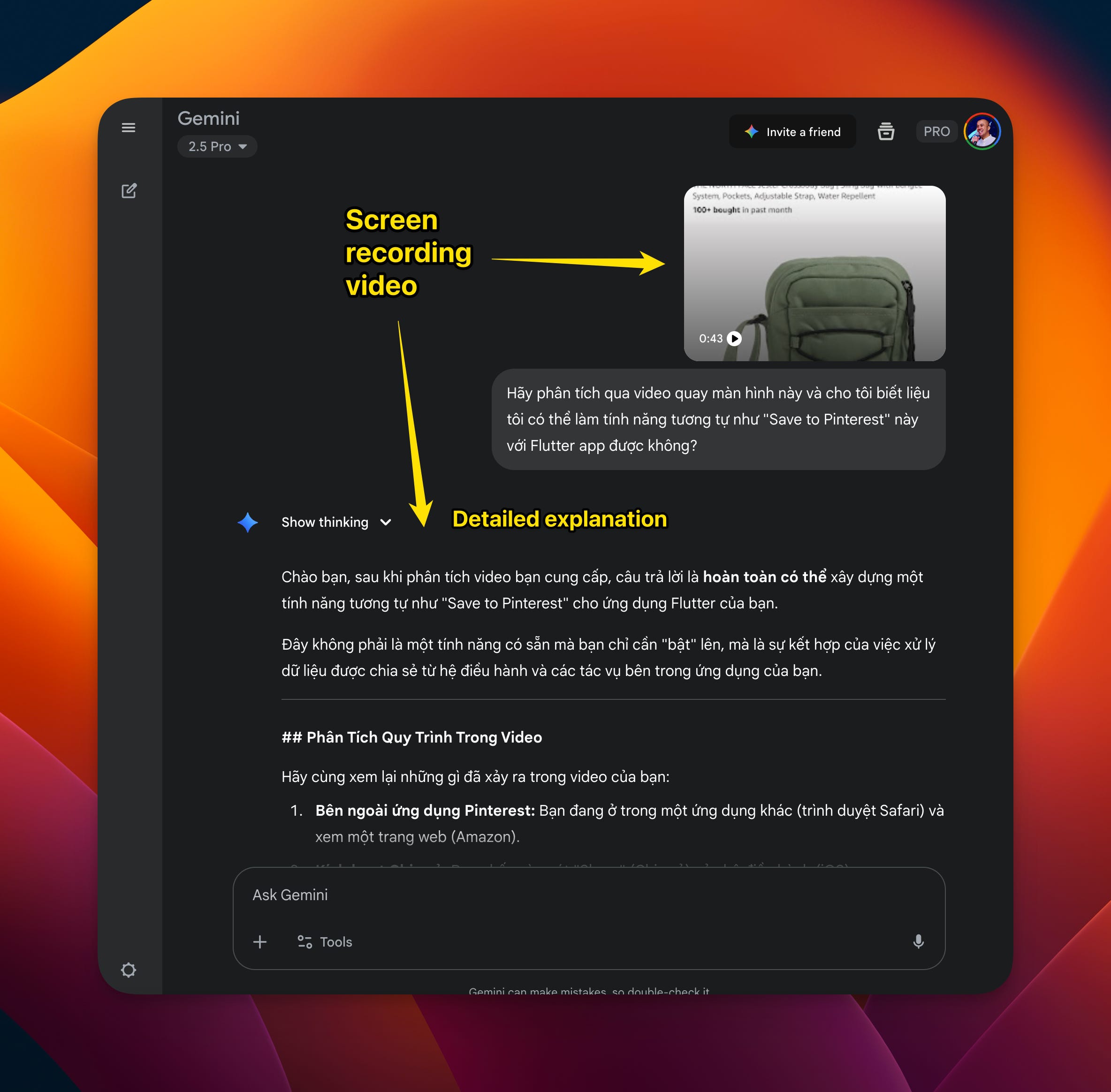
Không phải lúc nào bạn cũng hiểu rõ tình huống, mô tả cách reproduce lỗi và phán đoán được hướng giải quyết, quay màn hình lại và đưa cho Gemini (bản Web) để nhờ nó đoán ra các nguyên nhân gốc rễ hoặc đề xuất hướng xử lý là giải pháp không hề tồi.
Chỉ có điều là Gemini bản web thì không có context của codebase, nên trong prompt mình phải đưa thông tin đó vào, khá là mất công…
Cho nên mình quyết định tạo ra MCP này: Human MCP
Mục đích là để dùng Gemini API để phân tích hình ảnh, tài liệu (PDF, docx, xlsx,…) và video.
Thời gian đầu của ClaudeKit, mình đã cài đặt sẵn “Human MCP” mặc định.
Và bạn cần GEMINI_API_KEY trong env của “Human MCP” để nó có thể hoạt động.
Sau đó, Anthropic ra mắt Agent Skills!
Mọi người biết rồi đó: MCP cũng có vấn đề của nó, đó là nó quá ngốn context
Đây là ví dụ của Chrome Devtools MCP và PLaywright MCP:

Và Agent Skills sinh ra là để giải quyết vấn đề đó.
Nên mình đã chuyển toàn bộ tools của Human MCP thành Agent Skills, để chúng ta có thể có nhiều không gian trống trong context windows cho agents làm việc.
Do đó, GEMINI_API_KEY được di chuyển vào .claude/.env, bạn chỉ cần nhập giá trị vào đây là được.
Thông thường thì skills sẽ được kích hoạt tự động tuỳ thuộc vào ngữ cảnh mà agent đang xử lý.
Nhưng nếu bạn cần kích hoạt skill này một cách chủ động, chỉ cần prompt như sau: use ai-multimodal to analyze this screenshot: ...
Đơn giản như vậy thôi.
🎄 Ưu đãi Giáng Sinh
Code Hunt 2025: Bạn đã tìm thấy trứng! 🥚
Dùng mã
J1NGLEB3LLSđể được giảm 40% ClaudeKit. Chỉ còn 50 mã!